웹 프론트엔드 개발에서 사용자 경험을 향상시킬 수 있는 방법은 매우 다양합니다.
예를 들어, 렌더링과 네트워크 요청을 최적화하거나 정적 리소스 파일의 크기를 줄이는 등 성능 측면에서의 개선이 가능합니다. 또한 웹 사용에 어려움이 있는 분들을 위한 웹 접근성 개선, 로딩 시간이 길게 느껴지지 않도록 UI/UX를 개선하는 방법, 그리고 SEO(검색 엔진 최적화)를 개선하여 검색엔진에서 사이트의 세부 페이지가 어떤 식으로 구성되어있는지 정보를 제공하는 등 모두 사용자 경험을 높이는 중요한 요소입니다.
성능 최적화 방법은 무수히 많지만, 제가 실무에서 경험해본 바로는 최소한의 노력으로 최대의 성능 개선을 이끌어낼 수 있는 몇 가지 핵심적인 방법들이 있습니다.
이 글에서는 이러한 방법들을 중심으로 설명하도록 하겠습니다.
코드 스플리팅
웹 애플리케이션이 복잡해지고 규모가 커질수록 정적 번들 파일의 크기도 함께 증가하게 됩니다.
기본적으로, 브라우저는 단일 스레드이므로 모든 무거운 작업이 메인 스레드에서 수행됩니다. 즉, 웹 브라우저는 구문 분석, 레이아웃 및 페인트가 이루어지는 스레드인 메인 스레드에서 JavaScript 코드를 실행합니다. 특히 많은 기능을 제공하는 대규모 애플리케이션의 경우, 사용자가 페이지와 상호 작용하기 전에 메인 스레드가 코드를 평가하는 데 바쁩니다.
즉, 많은 기능을 가진 웹사이트를 아주 큰 하나의 자바스크립트로 번들링 한다면 처음부터 해당 번들에 포함된 모든 기능이 필요하지 않더라도 기다려야 하는 셈이죠.
Code Splitting은 이러한 문제를 해결하기 위한 효과적인 방법입니다. 전체 코드를 여러 개의 작은 번들로 나누어, 필요한 시점에 필요한 코드만 로드함으로써 초기 로딩 성능을 개선할 수 있습니다.
Dynamic Import
Dynamic Import는 코드 스플리팅을 적용하기 위한 가장 보편적인 방법입니다.
유저가 업로드한 엑셀을 파싱하여 테이블을 그려주는 페이지를 개발하고 있다고 생각해봅시다.
엑셀 파일의 컨텐츠를 쉽게 파싱할 수 있도록 도와주는 xlsx라는 유명한 라이브러리를 사용해보죠.
import * as xlsx from 'xlsx';
const parseExcel = (data) => {
const workbook = xlsx.read(data, read_opts);
// ...
};
const input = document.querySelector('input');
input.addEventListener('change', (e) => {
parseExcel(e.target.files[0]);
});짜잔 완성했습니다. 이제 PR을 올리고 일을 끝마치면 되겠군요.
하지만 xlsx 는 무겁기로 소문난 라이브러리 중 하나입니다. 서드파티 라이브러리의 용량을 확인할 수 있는 Bundle phobia에서 확인해보면 압축되어도 135.6kB나 되는 걸 볼 수 있습니다. 따로 코드 스플리팅 처리를 하지 않았다면 그대로 메인 JS 파일에 큰 용량이 포함될 겁니다.
const parseExcel = async (data) => {
const xlsx = await import('xlsx');
const workbook = xlsx.read(data, read_opts);
// ...
};이번에는 모듈을 동적으로 가져옵니다.
모듈 번들러는 동적 Import를 감지하면 모듈을 별도의 번들로 번들링합니다. 또한 나중에 별도의 HTTP 요청을 통해 해당 번들을 비동기적으로 로드하는 데 필요한 코드를 생성합니다.
다만 작은 문제가 있습니다. xlsx 모듈 번들은 사용자가 엑셀 파일을 업로드했을 때 다운로드 되므로 번들이 다운로드되는 동안 사용자에게 약간의 지연이 발생할 수 있습니다. 로딩 처리를 하여 이 문제를 해결해도 되겠지만 모듈 번들러를 이용하여 해당 페이지에 접속했을 때 미리 번들을 다운로드 받을 수 있도록 구성할 수 있습니다.
const parseExcel = async (data) => {
const xlsx = await import(/* webpackPrefetch: true */ 'xlsx');
const workbook = xlsx.read(data, read_opts);
// ...
};Webpack 을 사용한다면 동적 Import 구문에 힌트 지시문을 제공할 수 있습니다. 위 힌트에 따라 Webpack은 해당 모듈을 사용하는 페이지의 index.html 에 모듈을 prefetch 하는 link태그를 주입합니다.
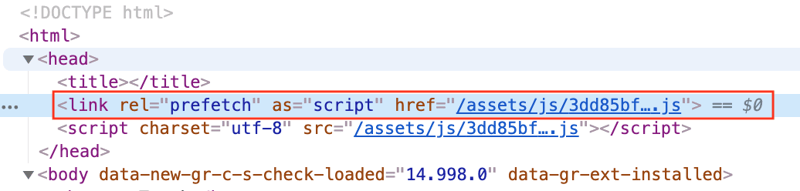
Rollup을 사용한다면 기본 동작으로 동적 Import가 사용되는 페이지의 index.html에 모듈을 preload하는 link 태그가 주입됩니다.
<link rel="modulepreload" crossorigin href="/assets/main.3949e347.js" />하지만 이럼에도 유저의 인터넷 환경에 따라 모듈이 언제 다운로드 될지 모르기에 로딩 처리가 필요할 것입니다.
따라서 무분별하게 적용하지 않고 초기 페이지 로딩 속도와 인터랙션 UX의 트레이드 오프를 고려하여 적용해보시는 것을 추천드립니다.
React.lazy()
React에서는 lazy와 Suspense를 사용하여 컴포넌트 레벨에서의 코드 스플리팅을 쉽게 구현할 수 있습니다.
React.lazy()는 동적 import()를 호출하는 함수를 인자로 받아, 별도의 청크로 분리될 컴포넌트를 반환합니다. 이렇게 분리된 컴포넌트는 모듈 번들러에서 실제로 렌더링될 때만 로드 되도록 번들링됩니다.
const HomePage = React.lazy(() => import('./pages/Home'));
const AboutPage = React.lazy(() => import('./pages/About'));
const ContactPage = React.lazy(() => import('./pages/Contact'));
function App() {
return (
<Suspense fallback={<LoadingSpinner />}>
<Routes>
<Route path="/" element={<HomePage />} />
<Route path="/about" element={<AboutPage />} />
<Route path="/contact" element={<ContactPage />} />
</Routes>
</Suspense>
);
}보편적으로 위와 같이 라우트 기반으로 코드 스플리팅을 적용합니다. 또는 규모가 아주 큰 컴포넌트나 모달과 같은 현재 표시되지 않는 컴포넌트에도 적용할 수 있습니다.
다만 React.lazy()를 사용할 때는 몇 가지 주의사항이 있습니다:
Suspense컴포넌트를 필수로 감싸Fallback UI를 설정하여야 합니다.- 서버 사이드 렌더링에서는
React.lazy()를 직접 사용할 수 없으며, 대신@loadable/component와 같은 라이브러리를 사용해야 합니다. - 너무 잦은 코드 스플리팅은 오히려 성능을 저하시킬 수 있으므로, 적절한 단위로 분할하는 것이 중요합니다.
자세한 사항은 공식문서에서 확인하실 수 있습니다.
Next 에서의 코드 스플리팅
Next.js에서는 코드 스플리팅이 기본적으로 적용되어 번들링이 자동으로 이루어집니다. 파일 시스템 기반의 라우팅 방식을 사용하여 각 페이지마다 개별적인 자바스크립트 번들이 생성되고, 사용자가 특정 페이지에 접근할 때 해당 번들만 로드됩니다.
그리고 의존성 모듈의 코드 스플리팅도 기본적으로 수행합니다. 페이지에서 불러오는 모듈들은 각각의 Vendor 자바스크립트 파일로 분할되어 사용하는 페이지에서 로드됩니다.
기본적으로 서버 컴포넌트는 자동으로 코드 스플리팅이 적용되며, streaming을 사용하여 서버에서 클라이언트로 UI 조각을 점진적으로 전송할 수 있습니다.
클라이언트 컴포넌트의 코드 스플리팅을 구성하기 위해서는 next/dynamic 을 사용할 수 있습니다.
'use client';
import { useState } from 'react';
import dynamic from 'next/dynamic';
// Client Components:
const ComponentA = dynamic(() => import('../components/A'));
const ComponentB = dynamic(() => import('../components/B'));
const ComponentC = dynamic(() => import('../components/C'), { ssr: false });
export default function ClientComponentExample() {
const [showMore, setShowMore] = useState(false);
return (
<div>
{/* Load immediately, but in a separate client bundle */}
<ComponentA />
{/* Load on demand, only when/if the condition is met */}
{showMore && <ComponentB />}
<button onClick={() => setShowMore(!showMore)}>Toggle</button>
{/* Load only on the client side */}
<ComponentC />
</div>
);
}const WithCustomLoading = dynamic(() => import('../components/WithCustomLoading'), {
loading: () => <p>Loading...</p>,
});dynamic() 함수는 React.lazy()와 Suspense를 기반으로 구현되어 있습니다. 따라서 dynamic()으로 불러온 컴포넌트는 이미 Suspense로 감싸져있기 때문에 그대로 쓰면 되고 Fallback UI를 설정하고 싶다면 dynamic()함수의 옵션으로 Fallback UI를 설정할 수 있습니다.
트리 쉐이킹
Tree shaking 은 JavaScript 컨텍스트에서 불필요한 코드를 제거하는 것을 설명하는 데 일반적으로 사용되는 용어입니다. - MDN
트리 쉐이킹은 번들러가 실제로 사용되는 코드만을 포함하고 사용되지 않는 코드는 최종 번들에서 제외하는 최적화 기법입니다. 마치 나무를 흔들어서 죽은 잎사귀들을 떨어뜨리는 것처럼, 불필요한 코드를 제거한다는 의미에서 이런 이름이 붙었습니다.
트리 쉐이킹이 필요한 경우
지금까지 자신의 프로젝트의 번들 사이즈를 점검해본 적이 없다면 아래와 같은 도구들을 통해 한 번 점검해보는 것을 추천드립니다:
이러한 도구들은 번들의 구성을 시각적으로 보여주어 불필요한 코드가 포함되었는지 쉽게 파악할 수 있게 해줍니다.
분석 결과를 보았을 때 아래와 같은 상황이라면 트리 쉐이킹 기법을 적극적으로 적용해보는 것을 추천드립니다.
- 특정 의존성 모듈이 사용량에 비해 번들 사이즈에 상당한 비중을 차지하는 경우
- 모노레포 프로젝트일 때, 공용 모듈의 사이즈가 사용량에 비해 번들 사이즈에 상당한 비중을 차지하는 경우
저는 현업에서 2번과 같은 상황의 프로젝트에 트리 쉐이킹을 적용하여 최대 50%의 번들 사이즈 감소를 이끌어냈습니다. 위와 같은 상황에서 어떻게 트리 쉐이킹을 적용할 수 있는지 알아보겠습니다.
모듈 시스템에 관하여
트리 쉐이킹이 효과적으로 동작하기 위해서는 ES 모듈 문법을 사용하고 사이드이펙트가 없는 순수한 코드를 작성해야 합니다.
아래 두 개의 코드 블럭을 비교해봅시다:
// math.js
module.exports.add = function add(a, b) {
return a + b;
};
module.exports.subtract = function subtract(a, b) {
return a - b;
};
module.exports.multiply = function multiply(a, b) {
return a * b;
};
module.exports.divide = function divide(a, b) {
return a / b;
};
// main.js
const { add, multiply } = require('./math.js');
console.log(add(2, 3));
console.log(multiply(4, 2));// math.js
export const add = (a, b) => a + b;
export const subtract = (a, b) => a - b;
export const multiply = (a, b) => a * b;
export const divide = (a, b) => a / b;
// main.js
import { add, multiply } from './math.js';
console.log(add(2, 3));
console.log(multiply(4, 2));결론부터 말하자면 위 두개의 코드 블럭이 번들링 되었을 때 ES 모듈 문법을 사용한 번들은 add, multiply 함수만 포함되고, CommonJS 문법을 사용한 번들은 add, multiply, subtract, divide 함수가 모두 포함됩니다.
CommonJS로 이루어진 모듈을 제대로 트리 쉐이킹 할 수 없는 이유에 대해 간략하게 알아보겠습니다.
CommonJS모듈은 런타임에 평가되므로 모듈 번들러는 모듈이 실제로 사용되는지 확인할 수 없습니다.CommonJS모듈은 모듈 객체를 내보내므로 모듈 번들러는 어떠한 모듈이 사용되고 있는지 확인할 수 없습니다.
모듈 번들러에 따라 내부 동작은 다르겠지만 기본적으로 트리 쉐이킹은 정적 분석(Static Analysis)을 통해 사용되지 않는 코드를 감지하고 제거하는 작업입니다. 따라서 런타임에 동적(그리고 동기적으로)으로 평가되는 CommonJS 모듈은 트리 쉐이킹이 제대로 동작하지 않습니다.
위의 CommonJS 예시에서 multiply 함수만을 가져오는 require 함수의 내부를 확인해 봅시다:
const { multiply } = require('./math.js');
console.dir(require.cache['/math.js'].exports);
console.dir(multiply);
require 함수의 내부를 확인해보면 multiply 함수만을 가져오고 있음에도 불구하고 cache 프로퍼티에 모든 함수가 포함되어 있음을 확인할 수 있습니다.
실행 컨텍스트 관점으로 생각했을 때 모든 함수의 데이터가 require 함수의 실행으로 closure로 캡슐화되어 있다고 볼 수 있습니다. 따라서, 모듈 번들러는 어떠한 함수가 쓰일지 알기 어렵기 때문에 트리 쉐이킹을 제대로 수행할 수 없게 되는 것입니다.
그렇지만 ES 모듈 문법을 사용하면 정적 분석을 통해 빌드 타임에 모듈간 관계를 파악할 수 있고, 이를 기반으로 사용되지 않는 코드를 제거하는 작업도 가능하게 됩니다.
Tree Shaking과 Module system에 관한 더 자세한 내용을 알기 쉽게 정리한 다른 분의 글이 있으니 궁금하신 분은 이 글을 읽어보시는 걸 추천드립니다.
트리 쉐이킹 기법에서 모듈 시스템의 중요성에 대해 알아보았으니 이제 어떻게 트리 쉐이킹을 적용할 수 있는지 알아보겠습니다.
의존성 모듈 최적화하기
- 특정 의존성 모듈이 사용량에 비해 번들 사이즈에 상당한 비중을 차지하는 경우
위 경우는 CommonJS로 번들된 라이브러리를 사용하고 있거나 라이브러리 전체를 import하고 있는 경우입니다.
- CommonJS로 번들된 라이브러리를 사용하고 있는 경우
- 라이브러리 전체를 import하고 있는 경우
node_modules 안에서 라이브러리의 빌드된 소스 코드를 보고 CommonJS 문법으로 번들되어 있는지 확인합니다. CommonJS 문법을 사용한다면 ES 모듈 문법을 지원하는지 확인해보고 지원하지 않는다면 비슷한 기능의 다른 라이브러리로 대체하는 것이 좋습니다.
// ❌ 좋지 않은 예시
import _ from 'lodash';
const result = _.get(obj, 'deeply.nested.property');
// ✅ 좋은 예시
import get from 'lodash/get';
// 혹은
import { get } from 'lodash';
const result = get(obj, 'deeply.nested.property');위 예제처럼 라이브러리 전체를 import 하는 것보다 필요한 함수만 import 하여서 모듈 번들러에게 사용되지 않는 코드는 제거하도록 만드는 것이 좋습니다.
모노레포 공용모듈 트리쉐이킹
여러분의 프로젝트가 모노레포로 구성되어 있다면 대부분 공용으로 사용하고 있는 함수나 타입, 컴포넌트 등을 따로 모듈화하여 사용하고 있을 겁니다.
이 때, 트리 쉐이킹이 적용되어 있지 않다면 특정 워크스페이스에서는 사용하지 않지만 공용 모듈에 모아져 있어 번들에 포함되는 경우가 생깁니다.
- CommonJS 문법을 사용하고 있는 경우
- 타입스크립트를 사용하고 공용 모듈을 tsc로 컴파일하여 사용하는 경우
ES 모듈 문법을 사용해 트리 쉐이킹이 정상적으로 동작되게 합시다.
이 경우, tsconfig 파일에서 module 옵션이 ES2015 이상으로 설정되어 있는지 확인해주세요. CommonJS 문법으로 컴파일 된 모듈을 사용하게 되면 트리 쉐이킹이 제대로 동작하지 않게 됩니다.
또는, 자바스크립트로 컴파일 하지 않고 타입스크립트 파일 자체를 모듈로 사용하는 방법도 있습니다. 이 방법이 파일을 수정했을 때 HMR이 적용되고, IDE에서 타입 참조를 하였을 때 원본 파일로 이동하게 되므로 추천하는 방법입니다.
메모이제이션
메모이제이션은 이전에 계산한 값을 저장해두고 동일한 입력이 들어왔을 때 재계산하지 않고 저장된 값을 반환하는 최적화 기법입니다. React에서는 불필요한 리렌더링을 방지하기 위해 컴포넌트나 값을 메모이제이션 할 수 있는 API를 제공합니다.
메모이제이션은 리렌더링을 최적화하는데 강력한 기법이긴 하지만 무분별하게 적용한다면 오히려 성능이 저하될 수 있습니다. 메모이제이션 자체 동작으로 인해 메모리 사용량이 증가하고 초기 렌더링 비용이 들기 때문에 대부분의 상황에선 React의 기본 최적화만으로도 충분한 성능을 보장합니다.
React 공식문서에선 컴포넌트가 리렌더링 될 때 인지할 수 있을 만큼의 지연이 없다면 메모이제이션이 필요하지 않습니다 라고 말합니다. 이 말인즉슨, 반대로 사람이 인지할 수 있을 만큼 성능상의 문제가 있다면 메모이제이션 기법이 굉장히 효과적일 수 있다는 겁니다. (근데 성능 문제의 대부분은 컴포넌트 로직을 잘못 작성해서 발생합니다.)
들어가기 전에, 프로젝트에서 불필요한 리렌더링이 발생하는 컴포넌트가 있는지 React 개발자 도구 Profiler를 통해 먼저 확인해보세요.
React.memo
React의 기본 동작은 부모 컴포넌트가 리렌더링되면 모든 자식 컴포넌트도 리렌더링하는 것입니다. 하지만 자식 컴포넌트의 props가 변경되지 않았다면 리렌더링이 불필요할 수 있습니다.
memo는 아래와 같은 상황에서 적용하는 것을 추천드립니다:
- 컴포넌트가 동일한 props로 자주 렌더링되는 경우
- 컴포넌트의 리렌더링 비용이 큰 경우
const TodoItem = ({ title, completed }) => {
return (
<li>
<input type="checkbox" checked={completed} />
<span>{title}</span>
</li>
);
};
export default React.memo(TodoItem);자식 컴포넌트의 props가 원시 타입이 아닌 객체 타입(원시타입 외 전부)일 경우 리렌더링될 때마다 새로운 주소를 참조하게 되므로 항상 다른 prop으로 인식하게 됩니다. 이 경우 참조 동일성을 유지하기 위해 useMemo 혹은 useCallback을 같이 사용해야 합니다. 그렇지 않다면 memo를 감싸봤자 비용만 들고 리렌더링 최적화 효과를 아예 얻지 못하게 됩니다.
useMemo와 useCallback
useMemo와 useCallback은 모두 메모이제이션을 위한 훅입니다. 둘의 차이점은 useMemo는 값을 메모이제이션하는 데 사용되고, useCallback은 함수를 메모이제이션하는 데 사용됩니다.
useMemo와 useCallback은 아래와 같은 상황에서 적용하는 것을 추천드립니다:
- 계산 비용이 큰 연산을 수행할 때 (
useMemo만 해당)- React 공식문서에서는
console.time()으로 측정하였을 때 연산 시간이 1ms 이상 걸린다면 메모이제이션을 고려해볼 수 있다고 말합니다. (링크)
- React 공식문서에서는
- 메모이제이션된 값을 다른 훅의 의존성 배열에서 사용할 때 (참조 동일성 유지)
memo로 감싼 자식 컴포넌트에 객체 타입의 prop을 전달할 때 (참조 동일성 유지)
function TodoList({ todos }) {
// ❌ 매 렌더링마다 새로운 객체 배열 생성
const visibleTodos = todos.map((todo) => ({
...todo,
isComplete: todo.status === 'completed',
}));
// ✅ todos가 변경될 때만 새로운 배열 생성
const visibleTodos = useMemo(() => {
return todos.map((todo) => ({
...todo,
isComplete: todo.status === 'completed',
}));
}, [todos]);
return (
<div>
{/* visibleTodos가 변경될 때만 리렌더링 */}
<MemoizedTodoItem todos={visibleTodos} />
</div>
);
}function ProductPage({ productId }) {
// ❌ 매 렌더링마다 새로운 함수 생성
function handleSubmit(orderDetails) {
// ...
}
// ✅ productId가 변경될 때만 새로운 함수 생성
const handleSubmit = useCallback(
(orderDetails) => {
// ...
},
[productId],
);
return (
<div>
{/* handleSubmit이 변경될 때만 리렌더링 */}
<MemoizedForm onSubmit={handleSubmit} />
</div>
);
}사실 메모이제이션은 본 글 서두에 적었던 최소한의 노력으로 최대의 성능 개선과는 거리가 있는 최적화 기법이라고 생각합니다. 그렇지만 특정 상황에서는 뛰어난 최적화 효과를 보여줄 수 있고, 특히 React의 렌더링 사이클과 많은 관련이 있기 때문에 이 단락을 추가하였습니다.
본 글에서는 간략하게 다루었지만 더 자세한 내용이 공식문서(useMemo), 공식문서(useCallback)에 나와있으니 꼭 보시는 걸 추천드립니다.
번외 (React forget)
위 내용을 보셨으면 느끼셨겠지만, 어떨 때 사용해야 하는지 감이 잘 안오고 드라마틱한 성능 개선을 기대하기도 어렵고 의존성 배열을 잘못 관리하면 버그를 유발할 가능성도 크다고 느껴집니다.
이러한 상황에서 React 팀은 개발자가 메모이제이션에 대해 일절 생각하지 않아도 되도록, 컴파일 단계에서 메모이제이션이 필요한 컴포넌트를 파악해 자동으로 메모이제이션을 해주는 React Compiler Beta를 24년 10월에 공식적으로 릴리즈 했습니다.
현재는 베타 버전이지만 RC(Release Candidate) 버전을 거쳐 정식 버전이 출시될 예정이며, 정식 버전 출시 이후에는 모든 앱과 라이브러리에서 React Compiler와 ESLint 플러그인을 사용하는 것을 강력히 권장할 예정이라고 합니다.
얼마나 성능 개선이 될지 궁금하신 분들은 React Compiler 공식문서를 참고하여 한 번 적용해보시면 좋을 것 같습니다.
Windowing
웹 애플리케이션에서 긴 목록이나 큰 데이터를 렌더링할 때, 모든 항목을 한 번에 렌더링하면 브라우저의 메모리 사용량이 급격히 증가하고, 초기 로딩 시간이 길어지며, 사용자 경험이 굉장히 안좋아질 수 있습니다. 특히 각 항목이 복잡한 컴포넌트라면 더더욱 그렇죠.
Windowing은 긴 목록에서 현재 화면에 보이는 항목만 렌더링하고 나머지는 필요할 때 렌더링하는 최적화 기법이고 React 공식문서에서도 권장하는 방법입니다.
아래와 같은 상황에서 사용한다면 효과적인 성능 개선을 누릴 수 있습니다.
- 한 번에 수백 개 이상의 항목을 렌더링해야 할 때
- 각 항목이 복잡한 컴포넌트로 구성되어 있을 때
- 스크롤 성능이 눈에 띄게 저하될 때
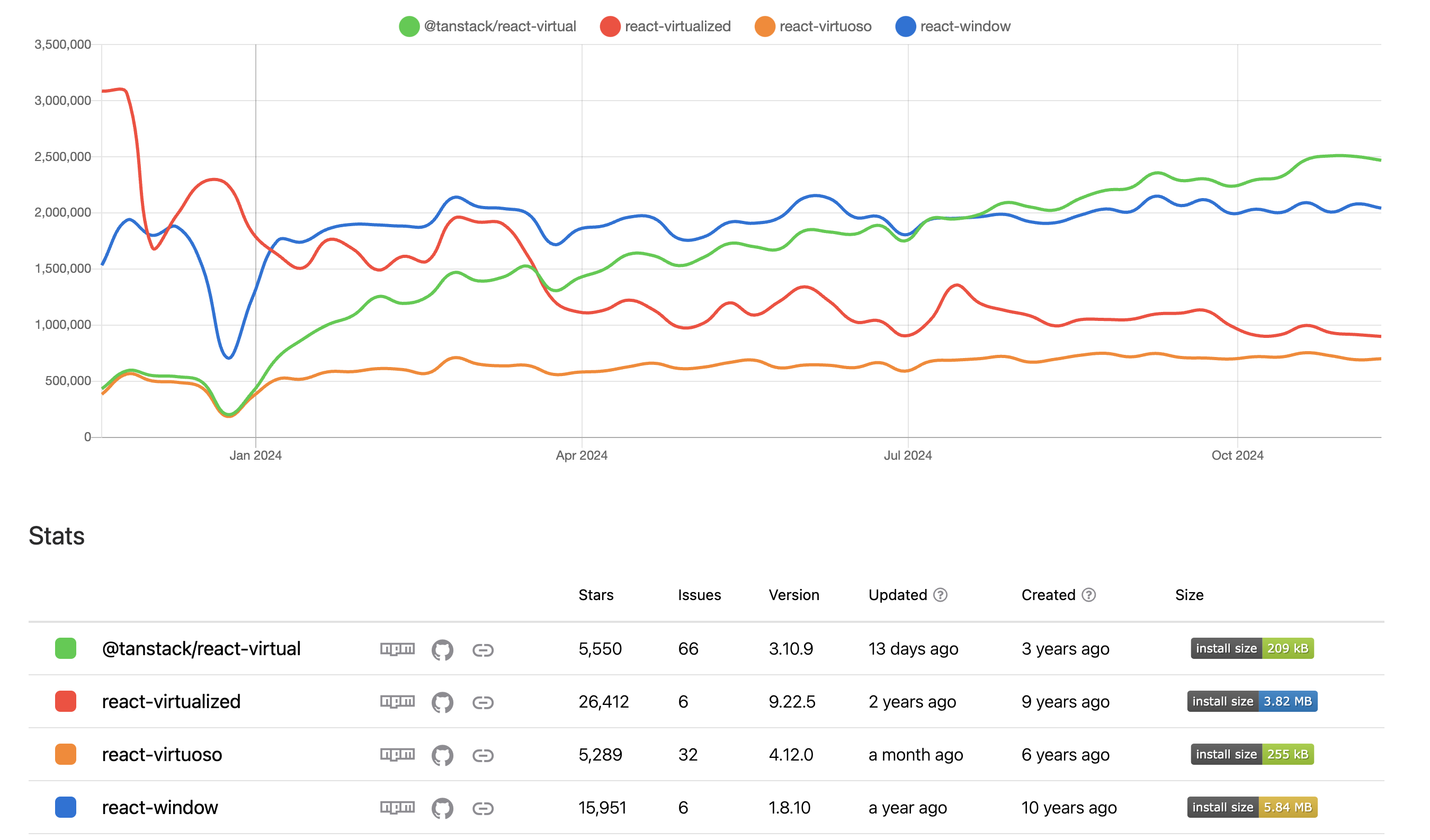
Windowing 기법을 간단하게 구현할 수 있게 해주는 라이브러리는 종류가 굉장히 다양합니다. 라이브러리의 용량, 업데이트 주기, 문서화 상태, 지원하는 기능 등 다양한 측면에서 비교해보았을 때 저는 @tanstack/react-virtual을 선택할 것 같습니다.
프론트엔드 개발을 하다보면 긴 목록을 렌더링하거나 무한 스크롤을 구현해야 하는 경우가 종종 있으니 그러한 상황이 오면 적용해보시는 걸 추천드립니다.
마치며
모든 최적화에는 비용이 따르지만 적절한 상황에 적절한 최적화를 선택하면 그 비용을 훨씬 뛰어넘는 성능 개선을 이룰 수 있습니다.
최적화를 무작정 적용하기보다는, 먼저 현재 프로젝트의 성능 병목을 정확히 파악하고 그에 맞는 방법을 선택하는 것이 중요합니다. 본 글에서 설명한 기법들 이외에도 이슈 상황에 따라 최적화 기법은 굉장히 다양하니 미리 어떤 최적화 기법들이 있는지 꾸준히 학습하고 적용해보세요!